
The Scaling Phenomenon in AI

Table of Contents
- Introduction: The Scaling Phenomenon in AI
- Understanding the Scaling Phenomenon
- The Two Faces of Scaling: Weak vs. Strong Scaling
- Power Constraints: The Key Limitation to AI Scaling
- The Debate: Is Scaling the Ultimate Path to AI Progress?
- Practical Implications of Scaling in AI
- Takeaway: Scaling as a Catalyst for AI Evolution
Introduction: The Scaling Phenomenon in AI
The field of artificial intelligence (AI) has witnessed unprecedented advancements over the last decade, largely driven by what is known as the scaling phenomenon. This concept suggests that increasing computational resources, such as data and model parameters, leads to significant improvements in AI capabilities. While this might seem intuitive, the implications of scaling are far-reaching and have sparked heated debates among researchers and technologists.
In this blog, we will delve deep into the scaling phenomenon, exploring how it influences AI progression, the theories that underpin it, and the controversies surrounding its long-term impact. We’ll also touch on the practical implications for industries leveraging AI and what the future might hold as AI systems continue to scale.
Understanding the Scaling Phenomenon
What is Scaling in AI?
Scaling in AI refers to the practice of increasing the resources allocated to AI models—typically by enlarging datasets, adding more model parameters, or boosting computational power. This concept is rooted in the observation that as these resources are scaled up, AI models tend to perform better on a wide array of tasks.
To break it down:
- Model Parameters: These are the internal settings that a machine learning model adjusts during training. Increasing the number of parameters generally allows models to capture more complex patterns in the data.
- Training Data: More data gives the model a richer set of examples from which to learn, reducing the likelihood of overfitting and improving generalization to new data.
- Compute Power: This encompasses the hardware capabilities (like GPUs and TPUs) that enable faster processing of larger datasets and more complex models.
The Bitter Lesson
One of the foundational ideas supporting the scaling phenomenon is what Richard Sutton, a pioneer in AI, calls the Bitter Lesson. Sutton argues that the most significant advances in AI have come from leveraging vast amounts of computation rather than relying on human insights to craft specialized algorithms for specific tasks.
This lesson suggests that, in the long run, general methods that can scale with increasing compute will outperform those that rely on human expertise and domain-specific tweaks. A vivid example is the progress seen in areas such as computer vision and natural language processing (NLP), where models like GPT-3 and DALL-E have achieved remarkable results by simply scaling up existing architectures rather than inventing new ones.
Scaling Laws: The Empirical Backbone
The scaling phenomenon isn’t just a theoretical concept—it’s backed by empirical evidence. Researchers have observed scaling laws in AI, which describe how model performance improves predictably as a function of the resources invested in training. These laws are often expressed as power laws, where the error rate decreases predictably with increased compute.
For example, in natural language processing, the performance of language models has been shown to improve consistently as the model size and dataset scale up. This relationship has been observed across various tasks, from image recognition to speech processing, making it a cornerstone of modern AI development.
The Two Faces of Scaling: Weak vs. Strong Scaling
Weak Scaling: Predictable Improvement
The concept of weak scaling in AI is relatively straightforward and primarily concerns the prediction that as you increase the scale—whether in terms of data, parameters, or compute—the model’s performance will improve. This improvement is often predictable, following the power laws mentioned earlier.
In practical terms, weak scaling is what allows AI researchers and engineers to plan and execute model training more efficiently. They can estimate the resources needed to achieve a certain level of performance, making it easier to budget for computing power and data acquisition.
Key Characteristics of Weak Scaling:
- Predictable: As you scale resources, the performance increase follows a known pattern.
- Resource-Intensive: Requires significant investment in compute power and data.
- Incremental Improvements: While the improvements are consistent, they are often incremental rather than transformative.
Strong Scaling: Emergent Abilities
Strong scaling, on the other hand, refers to the idea that as models scale up, they don’t just perform better in a predictable manner—they exhibit emergent abilities. These are capabilities that were not explicitly programmed into the model but appear as a result of the model’s increased complexity and exposure to vast amounts of data.
For instance, large language models like GPT-3 have demonstrated abilities such as few-shot learning, where the model can perform a new task after seeing only a few examples, or even zero-shot learning, where the task is performed without any specific examples during training. These emergent abilities are often surprising and difficult to predict, adding a layer of intrigue—and sometimes concern—to the discussion around scaling.
Key Characteristics of Strong Scaling:
- Unpredictable: Emergent abilities often appear unexpectedly as the model scales.
- Transformative: These abilities can significantly expand the model’s utility beyond its original design.
- Challenging to Evaluate: Because these abilities are emergent, they are harder to measure and validate using traditional benchmarks.
Power Constraints: The Key Limitation to AI Scaling

As AI models continue to scale, one of the most pressing challenges is the availability of power to support these massive training runs. Power constraints, which dictate how much electricity can be channeled to data centers, are increasingly becoming a critical bottleneck in the quest to scale AI training through 2030.
The Current Trend of AI Power Demand
AI model training already constitutes a rapidly growing portion of the total power usage of data centers. This growth is driven by the increasing complexity of models and the sheer volume of compute required for training. As of 2024, frontier AI models like Llama 3.1 405B require clusters of tens of thousands of GPUs, with each GPU demanding significant power. For instance, Nvidia’s H100 GPU, which is at the forefront of AI hardware, has a thermal design power (TDP) of 700 watts. However, after accounting for additional overheads such as cooling and power distribution, the effective power consumption per GPU can reach as high as 1,700 watts.
To put this into perspective, the power required for a single frontier AI training run today is equivalent to the annual energy consumption of tens of thousands of US households. The projected needs by 2030 are staggering—training runs are expected to be up to 5,000 times larger than those of Llama 3.1 405B, demanding upwards of 6 gigawatts (GW) of power. This is a significant portion of the total power currently consumed by all US data centers combined, which stands at approximately 20 GW.
The Feasibility of Meeting Future Power Demands
Meeting the power demands of future AI training runs will require a substantial expansion of data center power capacity. Several strategies have been proposed to address this challenge:
- On-Site Power Generation: Some companies are already securing power directly from large-scale energy facilities. For example, Amazon has secured up to 960 megawatts (MW) from a nuclear plant for its data center in Pennsylvania. On-site generation offers advantages such as reduced grid connection costs and increased reliability. However, the availability of such large-scale power deals is limited, and competition for these resources is high.
- Geographically Distributed Training: Another strategy involves distributing training across multiple data centers in different regions, thereby tapping into various power grids. This approach can help circumvent local power constraints and leverage the combined capacity of multiple regions. Companies like Google are already experimenting with this method, using distributed data centers to train large models like Gemini Ultra.
- Building New Power Plants: While constructing new power plants, particularly those using natural gas or solar energy, could provide the necessary power, this approach faces significant challenges. Building large-scale power plants requires substantial time and investment, with new plants taking anywhere from two to five years to become operational. Additionally, infrastructure-level bottlenecks, such as the time required to build transmission lines and transformers, could further delay the availability of new power sources.
The Upper Limits of Power Expansion
The potential to expand power capacity is subject to both technical and regulatory constraints. While the construction of new power facilities is theoretically scalable, practical considerations such as grid capacity, regulatory approvals, and environmental impact assessments could limit how quickly and extensively new power can be brought online. Moreover, the political landscape, particularly in relation to commitments to carbon neutrality, may further constrain the types of energy sources that can be utilized.
In summary, while power constraints are one of the most significant bottlenecks to AI scaling, there are strategies available to mitigate these challenges. However, the feasibility of scaling to the levels required by 2030 will depend heavily on the ability of AI labs and energy providers to innovate and collaborate in expanding the power infrastructure. Failure to meet these power demands could slow the pace of AI development, making it the most critical factor in determining the future trajectory of AI scaling.
The Debate: Is Scaling the Ultimate Path to AI Progress?
The scaling phenomenon has its proponents and detractors, each with compelling arguments.
Proponents’ View: Scaling as the Key to General Intelligence
Advocates of scaling argue that it is the most promising path toward achieving Artificial General Intelligence (AGI), a system that can perform any intellectual task that a human can. They believe that by continuing to scale AI models, we will eventually reach a point where these systems can understand and reason about the world in ways that are indistinguishable from human cognition.
Supporters point to the success of models like OpenAI’s GPT-3 and DeepMind’s AlphaGo as evidence that scaling can lead to breakthroughs that were previously thought to be years away. For them, the scaling phenomenon is not just a trend but a fundamental principle that will guide the future of AI.
Critics’ Perspective: The Limits of Scaling
Critics, however, argue that scaling alone is not a panacea. They point out several limitations:
- Diminishing Returns: As models get larger, the improvements in performance may become smaller, leading to a point where the cost of additional compute outweighs the benefits.
- Lack of Interpretability: Larger models are often black boxes, making it difficult to understand how they arrive at their decisions. This lack of transparency can be problematic, especially in high-stakes applications like healthcare or autonomous driving.
- Ethical and Environmental Concerns: The resources required to train large models are immense, raising questions about the environmental impact of scaling. Moreover, the deployment of such models can exacerbate issues like bias and inequality if not managed carefully.
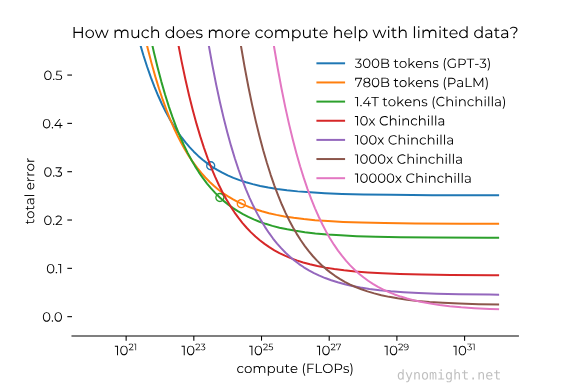
The Middle Ground: Hybrid Approaches
Some researchers advocate for a hybrid approach, combining the benefits of scaling with more sophisticated algorithms and better model architectures. They argue that while scaling is essential, it should be complemented by innovations in model design that improve interpretability, efficiency, and ethical alignment.
This middle-ground perspective suggests that a balanced approach—scaling where necessary but also focusing on algorithmic improvements—might be the best way to advance AI while mitigating some of the concerns associated with unchecked scaling.
Practical Implications of Scaling in AI
Industry Applications: From Research Labs to Real-World Impact
The scaling phenomenon is not just a topic of academic debate—it has real-world implications across various industries. Here are a few examples:
1. Healthcare
- Drug Discovery: AI models trained on vast datasets of molecular structures can predict the efficacy of new drug compounds, accelerating the drug discovery process.
- Medical Imaging: Scaled-up models can analyze medical images with high accuracy, assisting radiologists in diagnosing diseases like cancer at an earlier stage.
2. Finance
- Algorithmic Trading: Financial institutions use scaled AI models to analyze market trends and execute trades at speeds and accuracies beyond human capabilities.
- Fraud Detection: Larger datasets and models improve the detection of fraudulent activities, protecting consumers and businesses from financial crimes.
3. Customer Service
- Chatbots and Virtual Assistants: NLP models like GPT-3, when scaled, provide more nuanced and context-aware responses, improving customer satisfaction.
- Sentiment Analysis: Scaled models can analyze vast amounts of customer feedback to gauge sentiment and identify areas for improvement.
The Future of AI: What Lies Ahead?
As we look to the future, the scaling phenomenon promises to continue driving advancements in AI. However, several key challenges and questions remain:
- Sustainability: How can we balance the need for larger models with the environmental and economic costs?
- Regulation: As AI systems become more powerful, what regulatory frameworks will be necessary to ensure they are used responsibly?
- Ethical Considerations: How can we ensure that the benefits of scaled AI are distributed equitably and do not exacerbate existing biases or inequalities?
These are complex issues that will require collaboration across disciplines, from computer science to ethics, law, and public policy. The scaling phenomenon has brought us to the cusp of a new era in AI, but how we navigate the challenges it presents will determine whether this era is one of widespread benefit or unforeseen consequences.
Takeaway: Scaling as a Catalyst for AI Evolution
The scaling phenomenon in AI represents one of the most exciting and potentially transformative trends in technology today. By increasing compute, data, and model parameters, we have witnessed remarkable strides in what AI systems can achieve, from mastering complex games to generating human-like text.
However, as with any powerful tool, scaling comes with its own set of challenges and responsibilities. While it has proven to be a potent catalyst for AI evolution, it is not a one-size-fits-all solution. The future of AI will likely depend on our ability to harness the power of scaling while also addressing its limitations through innovation, regulation, and ethical stewardship.
As we continue to push the boundaries of what AI can do, the scaling phenomenon will undoubtedly play a central role. But the ultimate success of AI will hinge on our ability to balance this scaling with the broader considerations of sustainability, ethics, and societal impact.


