In the world of Artificial Intelligence (AI) and machine learning, particularly within the domain of Large Language Models (LLMs), test-time compute refers to the computational resources utilized during the inference phase—the process where a model generates outputs in response to user prompts or queries. Unlike the training phase, which is a resource-intensive but one-time endeavor, inference occurs every time the model is deployed, making the efficient management of test-time compute critical for both performance and practical scalability.
As the capabilities of LLMs continue to evolve, test-time compute has emerged as a pivotal factor in determining how effectively these models can perform tasks, ranging from natural language understanding to complex problem-solving. This article delves deep into the concept, exploring its importance, strategies, and implications for the broader AI ecosystem.
What Is Test-Time Compute?
In the world of Artificial Intelligence (AI) and machine learning, particularly within the domain of Large Language Models (LLMs), test-time compute refers to the computational resources utilized during the inference phase—the process where a model generates outputs in response to user prompts or queries. Unlike the training phase, which is a resource-intensive but one-time endeavor, inference occurs every time the model is deployed, making the efficient management of test-time compute critical for both performance and practical scalability.
As the capabilities of LLMs continue to evolve, test-time compute has emerged as a pivotal factor in determining how effectively these models can perform tasks, ranging from natural language understanding to complex problem-solving. This article delves deep into the concept, exploring its importance, strategies, and implications for the broader AI ecosystem.
The Significance of Test-Time Compute
The efficiency and allocation of compute during inference are crucial for practical applications of LLMs. Unlike training, where computational resources are expended upfront to build and optimize a model, inference happens repeatedly. Every query or task requires a fresh computational expenditure, making test-time compute a recurring cost. Therefore, enhancing test-time compute is essential for ensuring that LLMs remain efficient while delivering high-quality results.
Enhancing Model Performance
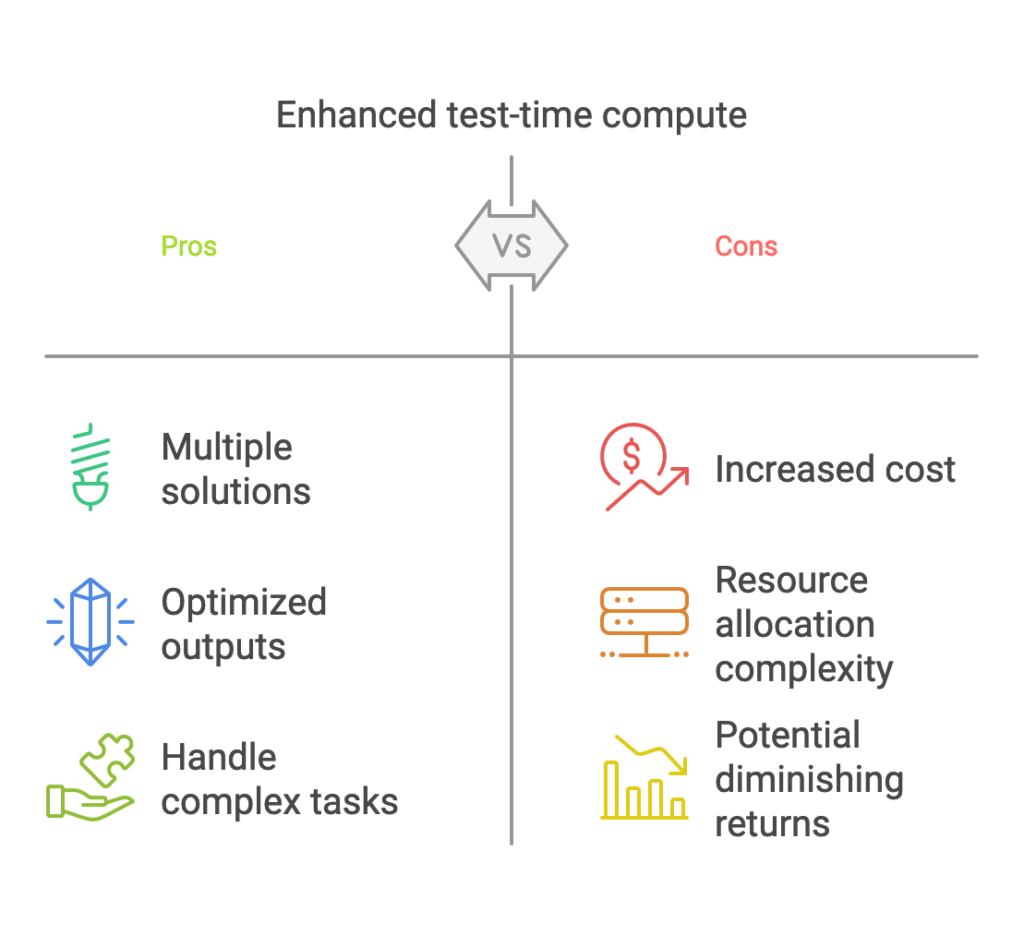
Allocating more computational resources during inference allows LLMs to:
Generate Multiple Solutions
Models can explore a variety of potential answers or solutions to a given prompt.
Evaluate and Optimize Outputs
By iteratively refining outputs, models can achieve greater accuracy and relevance, mimicking human cognitive processes.
Address Complex Tasks
Complex and nuanced queries benefit disproportionately from increased inference resources, as these tasks often require deeper reasoning and longer context windows.
Research increasingly shows that scaling test-time compute can sometimes yield more significant performance gains than increasing the size of the model or the quantity of training data. This finding underscores the importance of strategically leveraging inference-phase resources.
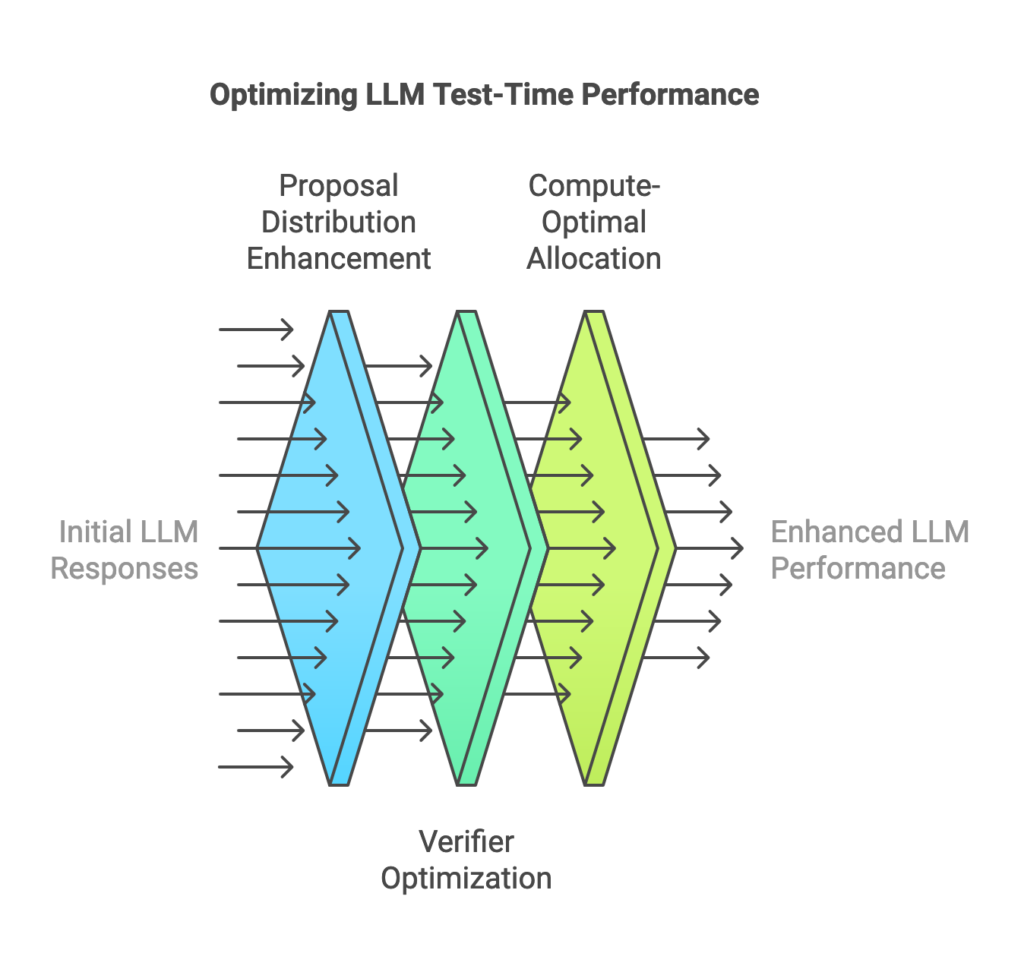
Strategies for Scaling Test-Time Compute
Optimizing test-time compute involves implementing sophisticated strategies that enable LLMs to maximize their performance during inference. Below are some notable approaches:
1. Proposal Distribution Enhancement
Proposal distribution strategies focus on refining how models generate and evaluate responses:
Sequential Revisions
LLMs iteratively improve their responses over multiple attempts, akin to a writer drafting and revising their work. This process enhances the coherence, accuracy, and depth of the final output.
Adaptive Distribution Updates
By tailoring response generation to the specific prompt, LLMs can dynamically adapt their approach, improving the relevance and contextual alignment of their answers.
2. Verifier Optimization
Verifier models play a crucial role in ensuring the quality of outputs by evaluating their correctness and relevance:
Process-Based Verifier Reward Models (PRMs)
These models assess each step in a solution or reasoning chain, guiding the LLM to arrive at accurate and logical conclusions.
Outcome-Supervised Reward Models (ORMs)
ORMs evaluate the final output, providing feedback on its overall quality. This method ensures that even if intermediate steps are imperfect, the end result meets desired criteria.
3. Compute-Optimal Allocation
Dynamically adjusting computational resources based on task complexity can lead to significant efficiency gains:
Simple Tasks
Allocate minimal compute to straightforward queries, conserving resources.
Challenging Problems
Deploy more resources for complex tasks, ensuring higher accuracy and performance without overburdening the system.
Studies have demonstrated that compute-optimal strategies often outperform traditional static approaches, achieving better results while using fewer computational resources overall.
Balancing Training and Inference Compute
One of the most intriguing aspects of test-time compute lies in its interplay with training-phase compute. The trade-offs between these two phases highlight the strategic decisions developers must make:
1. Enhancing Inference Over Training
In scenarios where training large models is computationally prohibitive, increasing test-time compute can compensate. Smaller models, when paired with robust inference strategies, can achieve performance levels comparable to larger, more extensively trained counterparts.
2. Task-Specific Requirements
For highly complex tasks, no amount of test-time compute can fully compensate for insufficient training. In such cases, additional training remains necessary to provide the model with a foundational understanding of the problem space.
The ability to balance these two dimensions effectively determines whether an AI system can deliver state-of-the-art performance while remaining cost-efficient.
Recent Advances in Test-Time Compute
The application of test-time compute strategies has already started transforming the field. Notable developments include:
OpenAI’s o3 and o3-mini Models
These models exemplify the practical application of test-time compute, achieving top-tier performance on diverse benchmarks. By optimizing inference processes, they demonstrate how smaller models can rival their larger counterparts.
Reward-Based Optimization Techniques
Both PRMs and ORMs have gained traction as tools for refining outputs and enhancing accuracy, paving the way for more reliable LLM applications.
These advancements underscore the growing recognition of test-time compute as a crucial lever for improving AI systems.
Trade-Offs and Implications
The optimization of test-time compute raises several critical considerations:
Cost Efficiency
Increasing inference resources can lead to higher operational costs, particularly for high-demand applications. Striking a balance between performance gains and cost containment is essential.
Latency and User Experience
Scaling test-time compute often introduces additional latency. Ensuring that enhanced performance does not compromise user experience is a key challenge.
Environmental Impact
As AI systems scale, their carbon footprint becomes a concern. Efficient use of test-time compute can mitigate the environmental impact of deploying LLMs at scale.
Future Directions
The evolution of test-time compute is closely tied to broader trends in AI research and deployment:
Dynamic Inference Systems
Adaptive frameworks that allocate resources in real-time based on task complexity are likely to become standard.
Integration with Training Innovations
As training methods continue to evolve, their integration with advanced inference strategies will enable even more efficient systems.
Ethical Considerations
Balancing performance with accessibility and sustainability will remain a central challenge as test-time compute strategies mature.
Takeaways
Test-time compute represents a critical frontier in the optimization of Large Language Models. By focusing on the efficient allocation of computational resources during inference, researchers and developers can unlock new levels of performance, reduce training dependencies, and enable more cost-effective deployments. As this field continues to evolve, its potential to transform AI applications across industries becomes increasingly evident.