The Rise of Large Language Models
LLMs are sophisticated AI systems that learn to generate human language by training on vast datasets containing billions of words and phrases. This training process allows them to master the nuances and structure of language, enabling them to perform tasks such as translation, sentiment analysis, chatbot interaction, and content generation. Some of the most popular LLMs include the Generative Pre-trained Transformer (GPT) models, such as BERT and GPT-3.
The training of these models involves complex mathematical operations and the processing of massive amounts of data, presenting a significant computational challenge. This is where GPUs come into play.
Why GPUs are Essential for LLM Training
GPUs are specifically designed for parallel processing, making them ideal for handling the computationally intensive tasks involved in LLM training. Unlike Central Processing Units (CPUs), which excel at handling sequential tasks one instruction at a time, GPUs can tackle thousands of tasks simultaneously. This parallel processing capability allows GPUs to efficiently process the many components involved in understanding and generating human language.
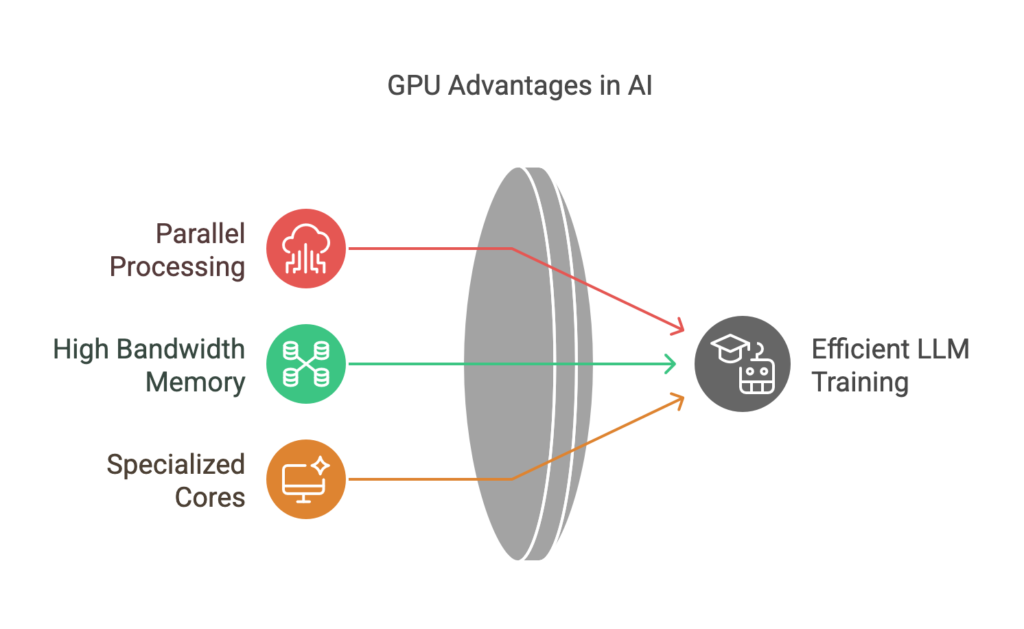
GPUs offer several key advantages for LLM training:
Parallel Processing
GPUs excel at handling the parallel nature of neural network operations, enabling them to process vast amounts of data concurrently.
High Bandwidth Memory
GPUs can quickly access and process large datasets, crucial for handling the extensive parameters of LLMs.
Specialized Cores
Modern GPUs include specialized cores like Tensor Cores, which are purpose-built for accelerating AI workloads, including the matrix multiplications that form the backbone of LLM computations.
Furthermore, GPUs offer high computational throughput, which is necessary for the complex mathematical operations involved in neural network training. They are particularly adept at matrix multiplication, a fundamental operation in deep learning. Not only are GPUs faster than CPUs for LLM training, but they are also more cost-effective in the long run due to reduced training time and energy consumption.
The LLM Training Process
Training an LLM is a multi-stage process that involves careful data preparation, model configuration, and iterative refinement:
Data Collection and Preprocessing
The first step involves gathering vast amounts of text data from various sources, such as books, articles, and code repositories. This data is then cleaned and preprocessed to remove noise, inconsistencies, and irrelevant information.
Tokenization
The preprocessed text is then broken down into smaller units called tokens, which can be words, subwords, or even characters. This tokenization process allows the model to represent and process language efficiently.
Model Configuration
A transformer-based neural network architecture is typically used for LLMs due to its effectiveness in natural language processing tasks. This architecture involves configuring various parameters, such as the number of layers, attention heads, and hidden units.
Model Training
The model is trained on the prepared data, learning to predict the next token in a sequence given the preceding tokens. This process involves numerous iterations and adjustments to the model’s internal weights to improve its predictive accuracy.
Fine-tuning
After initial training, the model is fine-tuned using techniques like Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT involves training the model on human-labeled data to align its responses with human expectations. RLHF further refines the model by using human feedback to reward desirable behaviors and discourage undesirable ones.
Types of GPUs Used for LLM Training
The increasing demands of LLMs and AI have driven rapid advancements in GPU technology, leading to the development of sophisticated language models. These advancements include:
Increased Memory Capacity
Larger models require more memory to process massive datasets. Modern GPUs offer substantial memory capacity, allowing researchers to build and train larger LLMs. However, it’s important to note that memory capacity is not the only factor; memory bandwidth and interconnect speed also play crucial roles in training large LLMs.
Faster Processing Speeds
GPUs with faster processing speeds significantly reduce training time, accelerating research and development.
Specialized Hardware
NVIDIA’s Tensor Core technology accelerates matrix computations, a core operation in deep learning, leading to faster and more efficient LLM training.
When choosing a GPU for LLM training, several factors need to be considered:
Model Size
Larger models with more parameters require GPUs with higher memory capacity and computational power.
Precision
The numerical precision used for representing model parameters (e.g., FP32, FP16, INT8) affects memory requirements and computational efficiency.
Batch Size
The number of training examples processed simultaneously impacts memory usage and training speed.
Some of the leading NVIDIA GPUs designed for LLM training include:
| GPU Name | CUDA Cores | Memory Capacity | Memory Bandwidth | TDP |
|---|---|---|---|---|
| NVIDIA H100 | 18,432 | 80GB HBM3 | 3 TB/s | 350W (SXM) / 700W (SXM5) |
| NVIDIA A100 | 6,912 | 40GB/80GB HBM2e | 1.6 TB/s (40GB) / 2 TB/s (80GB) | 250W (PCIe) / 400W (SXM) |
| NVIDIA L40 | 18,176 | 48GB GDDR6 | 864 GB/s | 300W |
| NVIDIA RTX 4090 | 16,384 | 24GB GDDR6X | 1008 GB/s | 450W |
| NVIDIA T4 | 2,560 | 16GB GDDR6 | 320 GB/s | 70W |
In addition to NVIDIA, AMD also offers GPUs suitable for LLM training, such as the AMD Radeon Pro W7900. This GPU features the latest RDNA3 architecture with advanced vector processing capabilities and high-bandwidth memory operations, making it well-suited for handling the computational demands of LLM training.
Hardware Platforms for LLM Training
While individual GPUs provide significant computational power, training large LLMs often requires scaling beyond a single device. This is where specialized hardware platforms come into play:
NVIDIA DGX Systems
NVIDIA DGX systems are full-stack solutions designed for enterprise-grade machine learning. These systems integrate high-performance NVIDIA GPUs with optimized software and networking to provide a powerful and scalable platform for LLM training.
Software Frameworks and Libraries
Several software frameworks and libraries are crucial for training LLMs on GPUs. These frameworks provide the necessary tools and functionalities for building, training, and deploying these models efficiently. When choosing a machine learning framework, several factors need to be considered:
Type of Model
Different frameworks may be better suited for different types of machine learning models, such as classification, regression, or neural networks.
Training Method
The chosen framework should support the desired training method, such as supervised learning, unsupervised learning, or reinforcement learning.
Targeted Hardware
The framework should be compatible with the available hardware, including CPUs, GPUs, and other accelerators.
Some of the key frameworks and libraries include:
PyTorch
A popular open-source machine learning framework that provides a flexible and efficient platform for LLM training.
Megatron-DeepSpeed
A powerful library that combines the strengths of Megatron-LM and DeepSpeed, enabling efficient distributed training of large models.
Transformers
An open-source library that provides general-purpose architectures like BERT, ROBERTA, and GPT-2 for Natural Language Understanding (NLU) and Natural Language Generation (NLG).
DeepSpeed
A deep learning optimization library that makes distributed training and inference easy and efficient.
Colossal-AI
A library that provides various tools for efficiently distributing training workloads and optimizing heterogeneous memory management.
NVIDIA NeMo
An end-to-end, cloud-native framework for building, customizing, and deploying generative AI models.
Fast-LLM
An open-source library designed for fast, scalable, and cost-efficient LLM training on GPUs.
LLMTools
A user-friendly library for running and fine-tuning LLMs in low-resource settings.
Llama Index
A data framework for integrating LLMs with various data sources, particularly for retrieval-augmented generation (RAG) applications.
These frameworks and libraries often work in conjunction with programming languages like Python and C++ to facilitate the development and training of LLMs.
Optimizing Communication in LLM Training
Efficient communication between GPUs is crucial for achieving high performance in LLM training, especially when scaling to large clusters. One technique for optimizing communication is compression-assisted MPI collectives. MPI (Message Passing Interface) is a standard for inter-process communication commonly used in distributed computing. By compressing the data exchanged between GPUs during MPI collectives, the communication overhead can be significantly reduced, leading to improved training efficiency.
Measuring LLM Training Efficiency
While fitting LLMs on a single GPU is essential, it’s important to consider the concept of “GPU Hours” as a more comprehensive measure of efficiency. GPU Hours represent the total amount of time spent training the model on a GPU, taking into account both the model’s size and the training duration. This metric helps to evaluate the overall cost and resource utilization of LLM training.
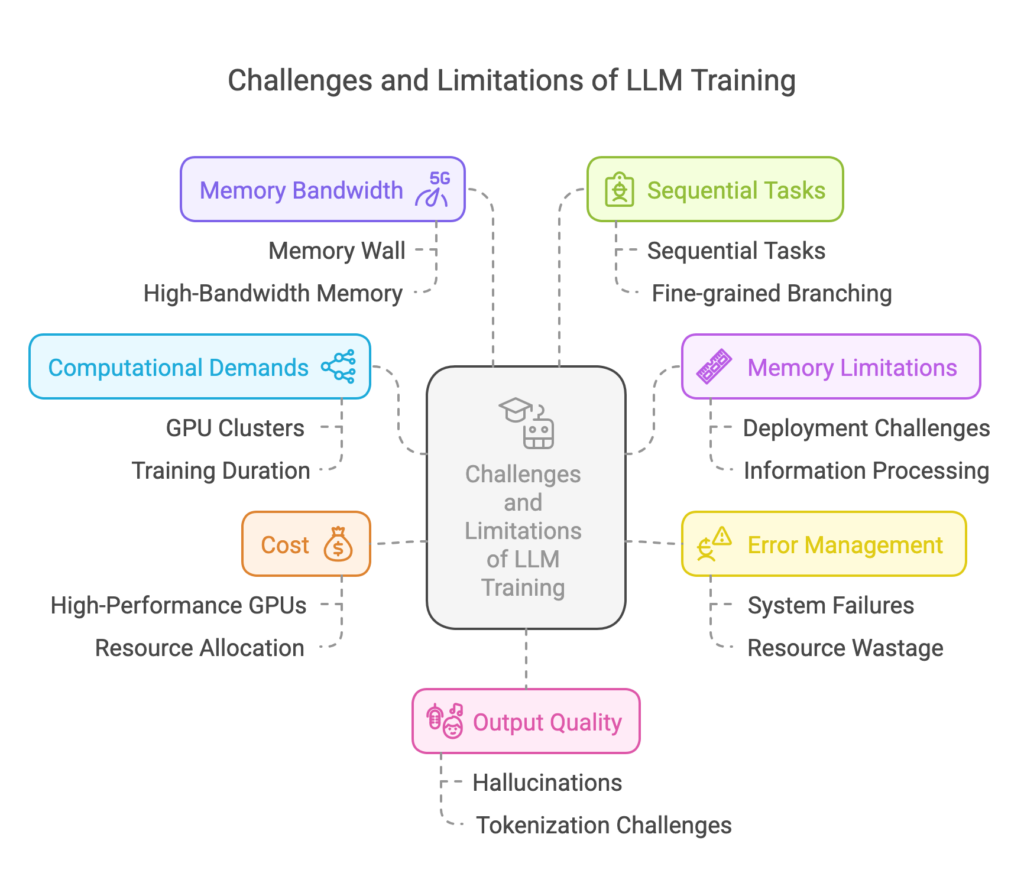
Challenges and Limitations
While GPUs have significantly accelerated LLM training, there are challenges and limitations associated with their use:
High Computational Demands
Training LLMs requires immense computational power, necessitating extensive GPU clusters. For example, training GPT-3 with its 175 billion parameters would take 288 years on a single NVIDIA V100 GPU.
Memory Limitations
LLMs demand substantial memory due to their processing of vast amounts of information. This can pose difficulties, particularly when attempting to deploy them on memory-constrained devices.
Error Management and System Reliability
Large-scale training risks errors and system failures. Without effective error recovery, training can be interrupted, wasting resources and increasing costs. Meta, for example, encountered various hardware failures during their LLM training, including GPUs falling off the PCIe bus, uncorrectable errors in DRAM and SRAM, and network cable failures.
Cost
Training LLMs requires significant financial investments, particularly in high-performance GPUs. Inefficient resource allocation can lead to skyrocketing costs. The cost of training a single LLM can range from tens of thousands to millions of dollars, depending on the model size and the amount of data used.
Memory Bandwidth Bottlenecks
Memory bandwidth can limit training performance, even with high-bandwidth memory stacks like HBM. This “memory wall” challenge arises because memory systems haven’t kept pace with the rapid increase in GPU computational power.
Sequential Tasks and Fine-grained Branching
GPUs are not well-suited for all types of problems. Sequential tasks, where each step depends on the previous one, and fine-grained branching, where the code execution path varies significantly between threads, can limit GPU performance.
Overhead for Smaller Networks
For smaller neural networks, the overhead of setting up computation on the GPU may outweigh the speedup gained from parallel processing. It’s important to benchmark CPU vs. GPU performance to determine the optimal hardware for a given task.
Limited Bandwidth of Integrated GPUs
Integrated GPUs, which share system memory with the CPU, often have limited memory bandwidth, which can hinder LLM training.
Output Quality and Hallucinations
LLMs can sometimes generate outputs that are factually incorrect or incoherent, referred to as “hallucinations.” These hallucinations can be problematic in applications where accuracy and reliability are critical.
Tokenization Challenges
Tokenizers, which break down text into smaller units, can introduce challenges such as computational overhead, language dependence, and information loss.
Parallelism Strategies for LLM Training
To overcome the limitations of training large LLMs on a single GPU, various parallelism strategies are employed:
Data Parallelism
In data parallelism, the same model is replicated on multiple GPUs, and each GPU processes a different portion of the training data. This allows for faster training by distributing the workload.
Model Parallelism
In model parallelism, different parts of the model are assigned to different GPUs. This is necessary when the model is too large to fit on a single GPU. Naive model parallelism can be inefficient due to idle time and communication overhead. Techniques like GPipe address these limitations by optimizing the partitioning of the model and the flow of data between GPUs.
Pipeline Parallelism
In pipeline parallelism, the model is divided into stages, and each stage is assigned to a different GPU. This allows for concurrent execution of different parts of the model, further improving training speed.
These parallelism techniques are often used in combination to maximize training efficiency and scalability.
Future Trends
The future of GPU technology for LLM training promises continued advancements and innovations:
AI-Specific Hardware
GPUs are evolving to include more AI-specific hardware, such as dedicated inference accelerators and GPUs with multiple Tensor Cores. This trend is driven by the increasing demand for specialized hardware that can efficiently handle the unique computational requirements of AI workloads, including LLMs.
Heterogeneous Architectures
The future will see increased integration of CPUs, AI accelerators, and FPGAs (Field-Programmable Gate Arrays) with GPUs. This integration will enable more flexible and efficient computing systems that can adapt to a wider range of AI tasks.
Unified Memory and Chiplet Design
Unified memory architectures and chiplet designs will enable more efficient and scalable GPUs. Unified memory allows CPUs and GPUs to share the same memory space, reducing data transfer overhead. Chiplet designs allow for more modular and customizable GPUs, enabling the development of specialized hardware for specific AI workloads.
Addressing the Memory Wall
Innovations like Tensor Cores and unified memory architectures are being developed to address the “memory wall” challenge, which limits the performance of LLMs due to memory bandwidth bottlenecks.
Alternative Hardware Platforms
While GPUs are currently the dominant hardware platform for LLM training, alternative platforms are emerging:
TPUs (Tensor Processing Units)
Google’s TPUs are specifically designed for machine learning workloads and offer high performance for LLM training.
FPGAs (Field-Programmable Gate Arrays)
FPGAs offer flexibility and customization, allowing for the development of hardware tailored to specific LLM training needs.
CPUs with Specialized Instructions
CPUs are evolving to include specialized instructions that accelerate AI workloads, potentially making them more competitive with GPUs for LLM training.
However, these alternatives currently lag behind GPUs in terms of overall performance and maturity for LLM training.
Open-Source LLMs
The development of open-source LLMs is democratizing access to this powerful technology:
LLaMA 3.1
Meta’s LLaMA 3.1 is a series of open-source LLMs that offer high performance and support for a wide range of NLP tasks. The latest version includes models with up to 405 billion parameters and an increased context length of 128,000 tokens, enabling improved performance on complex reasoning tasks.
GPT-NeoX-20B
Developed by EleutherAI, GPT-NeoX-20B is a 20 billion parameter LLM that has shown strong performance on various language understanding and knowledge-based tasks.
Evaluating LLM Performance
Evaluating the performance of LLMs is crucial for ensuring their accuracy, reliability, and safety. DeepEval is an open-source framework that provides tools and metrics for evaluating LLM applications. It offers various metrics to assess aspects such as answer relevancy, factual accuracy, and bias detection.
Security in LLM Training
As LLMs become more prevalent, ensuring the security of their training process is paramount. Research is ongoing to develop secure distributed LLM training frameworks that protect model parameters and data from malicious actors.
Cost Optimization in LLM Deployment
The cost of deploying and running LLMs can be significant. FrugalGPT is an approach that aims to reduce these costs by strategically selecting the most appropriate and cost-effective model for a given task.
Case Studies
Several successful case studies demonstrate the effectiveness of GPUs in LLM training:
MegaScale
A production system developed by Meta for training LLMs at the scale of more than 10,000 GPUs, achieving high training efficiency and stability. This case study highlights the challenges of scaling LLM training to such a large scale and the importance of factors such as hardware reliability, fast recovery on failure, efficient preservation of the training state, and optimal connectivity between GPUs.
Perplexity
An API tool powered by NVIDIA GPUs and optimized for fast LLM inference with NVIDIA TensorRT-LLM. This case study demonstrates how GPUs can be used to accelerate LLM inference, enabling real-time applications and reducing costs.
LILT
A generative AI platform that leverages NVIDIA GPUs and NVIDIA NeMo for faster translation of time-sensitive information at scale. This case study showcases the use of GPUs in a real-world application, highlighting the benefits of increased throughput and scalability.
Scaling LLM Training
Scaling LLM training to thousands of GPUs presents unique challenges. As model size and data volume increase, ensuring efficient communication between GPUs and maintaining high training stability become critical. Techniques such as compression-assisted MPI collectives and optimized parallelism strategies are essential for achieving optimal performance and scalability.
LLM Research and Development
The field of LLM research and development is rapidly evolving, with new models and techniques emerging constantly. Milestone papers have introduced innovations such as the transformer architecture, scaling laws for neural language models, and techniques for improving model efficiency and generalization.
Hardware Considerations for LLM Training
When setting up hardware for LLM training, several considerations and best practices should be kept in mind:
Budget
LLM training requires high-performance hardware, which can be expensive. Prioritize components based on budget and the scale of training planned.
Future-Proofing
Aim for hardware that can handle future LLMs, as model sizes and complexity continue to increase.
Cloud vs. On-Premises
Consider whether to build an on-premises setup or utilize cloud services, which offer flexibility and scalability.
Optimization
Efficient code and model optimization techniques can reduce hardware requirements and training time.
Monitoring and Maintenance
Regularly monitor hardware to detect issues early and perform routine maintenance.
Conclusion
GPUs have become indispensable for training large language models, enabling the development of sophisticated AI systems that can understand and generate human-like text. The advancements in GPU technology, coupled with innovative software frameworks and libraries, have significantly accelerated LLM training and paved the way for new possibilities in artificial intelligence. While challenges and limitations remain, ongoing research and development efforts continue to push the boundaries of GPU capabilities, promising even more powerful and efficient LLM training in the future.
One of the key challenges in the field of LLMs is the shortage of skilled professionals who can effectively develop, train, and deploy these complex models. This talent shortage has significant implications for the future of LLMs, potentially hindering their adoption and limiting their full potential. Addressing this challenge through education, training, and collaboration will be crucial for the continued advancement of LLMs and their successful integration into various applications.