Introduction to Vector Databases
In the rapidly evolving landscape of artificial intelligence (AI), vector databases have emerged as a powerful tool for managing and searching high-dimensional data. Unlike traditional databases that store structured data in tables and rows, vector databases are specifically designed to handle unstructured data, such as text, images, and audio, by representing them as numerical vectors in a high-dimensional space. This unique approach enables AI systems to perform complex tasks like semantic search, recommendation systems, and computer vision with unprecedented efficiency and accuracy.
What are Vector Databases?
Vector databases are a type of database management system that specializes in storing, indexing, and searching high-dimensional vectors. These vectors are mathematical representations of data points in a multi-dimensional space, where each dimension corresponds to a specific feature or attribute of the data. By encoding data as vectors, vector databases can capture the inherent relationships and similarities between data points, enabling AI systems to perform advanced analytics and make intelligent decisions.
The Rise of Vector Databases in AI
As AI continues to advance, the need for efficient and scalable solutions for managing and searching high-dimensional data has become increasingly critical. Traditional databases, such as relational databases or NoSQL databases, are not well-suited for handling the complex and unstructured nature of AI data. Vector databases, on the other hand, are specifically designed to address these challenges by providing a fast and flexible way to store, index, and search high-dimensional vectors.
The rise of vector databases in AI can be attributed to several factors:
- The exponential growth of unstructured data: With the proliferation of digital devices and the internet, the amount of unstructured data generated every day is staggering. Vector databases provide a scalable solution for managing and analyzing this data effectively.
- The need for real-time processing: AI applications often require real-time processing of large volumes of data. Vector databases offer fast query speeds and low latency, enabling AI systems to deliver results in real-time.
- The importance of similarity search: Many AI tasks, such as semantic search, recommendation systems, and anomaly detection, rely on the ability to find similar data points in a high-dimensional space. Vector databases excel at performing similarity searches, making them an essential tool for AI applications.
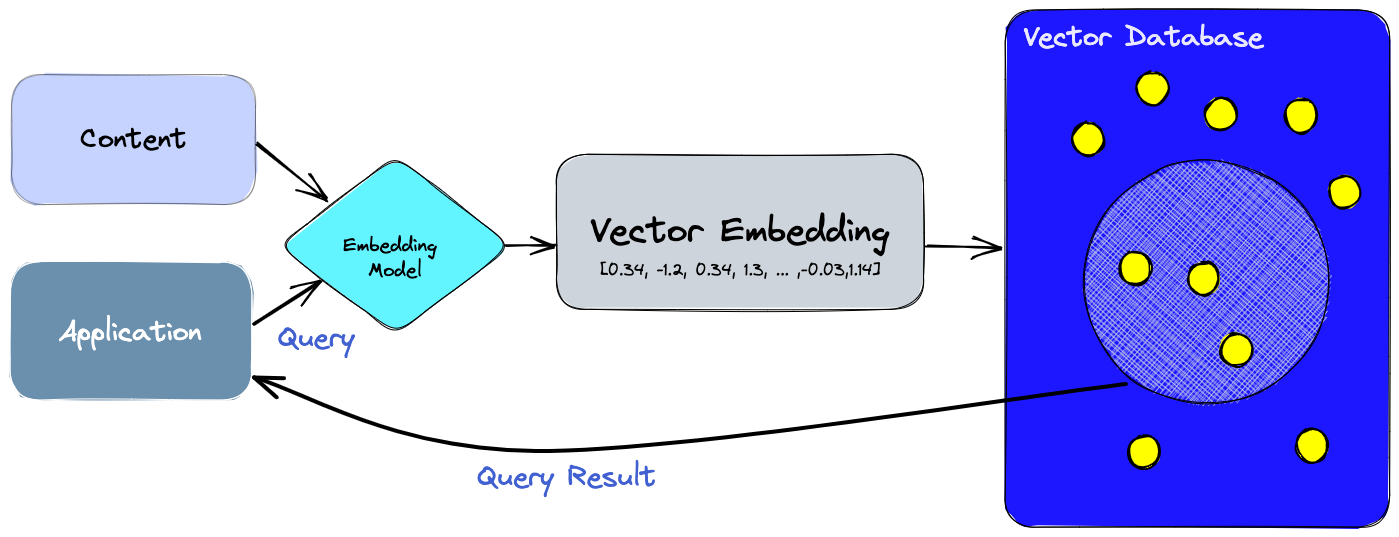
Understanding Embeddings and High-Dimensional Data
To fully grasp the significance of vector databases in AI, it’s essential to understand the concept of embeddings and high-dimensional data.
Embeddings: Representing Data as Vectors
Embeddings are a way of representing data as numerical vectors in a high-dimensional space. The process of creating embeddings involves mapping the original data, such as text, images, or audio, to a vector representation that captures the essential features and relationships of the data.
For example, in natural language processing (NLP), word embeddings are used to represent words as dense vectors. These vectors are learned from large corpora of text data using techniques like Word2Vec or GloVe. The resulting embeddings capture the semantic and syntactic relationships between words, allowing AI systems to understand and process natural language more effectively.
Similarly, in computer vision, image embeddings are used to represent images as vectors. Convolutional neural networks (CNNs) are typically employed to extract features from images and generate embeddings that capture the visual characteristics of the image. These embeddings can then be used for tasks like image classification, object detection, and similarity search.
High-Dimensional Data: The Challenge of Curse of Dimensionality
High-dimensional data refers to data that has a large number of features or attributes. In the context of vector databases, high-dimensional data is represented by vectors with hundreds or even thousands of dimensions.
The challenge with high-dimensional data is known as the “curse of dimensionality.” As the number of dimensions increases, the volume of the space grows exponentially, making it increasingly difficult to perform meaningful analysis or search operations. Traditional indexing techniques, such as B-trees or hash tables, become ineffective in high-dimensional spaces due to the sparsity of the data.
Vector databases address the curse of dimensionality by employing specialized indexing and search algorithms that are optimized for high-dimensional data. These algorithms, such as approximate nearest neighbor (ANN) search or locality-sensitive hashing (LSH), can efficiently find similar vectors in a high-dimensional space, even with a large number of data points.
Similarity Search: The Core of Vector Databases
At the heart of vector databases lies the concept of similarity search. Similarity search, also known as nearest neighbor search, is the process of finding the most similar vectors to a given query vector in a high-dimensional space.
Nearest Neighbor Search
In nearest neighbor search, the goal is to find the k nearest neighbors to a query vector, where k is a user-defined parameter. The similarity between vectors is typically measured using a distance metric, such as Euclidean distance or cosine similarity.
The basic idea behind nearest neighbor search is to compare the query vector with all the vectors in the database and return the k vectors with the smallest distances. However, this brute-force approach becomes impractical for large-scale datasets due to its computational complexity.
Approximate Nearest Neighbor (ANN) Search
To overcome the scalability limitations of exact nearest neighbor search, vector databases employ approximate nearest neighbor (ANN) search algorithms. ANN search trades off a small amount of accuracy for significant gains in speed and scalability.
ANN search algorithms work by constructing an index structure that partitions the high-dimensional space into regions or clusters. When a query vector is provided, the algorithm searches only the most promising regions, based on the index structure, to find the approximate nearest neighbors. This approach significantly reduces the number of comparisons required, making ANN search much faster than exact nearest neighbor search.
Some popular ANN search algorithms used in vector databases include:
- Locality-Sensitive Hashing (LSH): LSH is a probabilistic technique that maps similar vectors to the same hash bucket with high probability. By comparing only the vectors within the same or nearby hash buckets, LSH can efficiently find approximate nearest neighbors.
- Hierarchical Navigable Small World (HNSW): HNSW is a graph-based indexing method that constructs a multi-layer hierarchical structure of interconnected nodes. The search process navigates through the graph, starting from the top layer and progressively refining the search in the lower layers, to find the approximate nearest neighbors.
- Product Quantization (PQ): PQ is a compression technique that divides the high-dimensional space into subspaces and quantizes each subspace separately. By representing vectors as a combination of quantized subvectors, PQ can significantly reduce the storage and computational requirements of similarity search.
Benefits of Similarity Search in AI
Similarity search is a fundamental operation in many AI applications, enabling systems to find relevant information, make recommendations, and detect patterns in high-dimensional data. Some of the key benefits of similarity search in AI include:
- Efficient information retrieval: Similarity search allows AI systems to quickly find relevant documents, images, or other data points based on their content or features, improving the efficiency and accuracy of information retrieval tasks.
- Personalized recommendations: By finding similar items or users based on their preferences or behavior, similarity search enables AI-powered recommendation systems to provide personalized suggestions and improve user engagement.
- Anomaly detection: Similarity search can be used to identify unusual or anomalous data points by measuring their distance from the normal patterns or clusters in the high-dimensional space, helping AI systems detect fraud, errors, or security threats.
- Pattern recognition: By analyzing the similarity between data points, AI systems can discover hidden patterns, relationships, or trends in high-dimensional data, enabling tasks like clustering, classification, and prediction.
Benefits of Using Vector Databases in AI
Vector databases offer several key benefits for AI applications that deal with high-dimensional data:
Efficient Storage and Retrieval
Vector databases are designed to store and retrieve high-dimensional vectors efficiently. They use specialized data structures and indexing techniques, such as locality-sensitive hashing (LSH) or hierarchical navigable small world (HNSW), to partition the vector space and enable fast similarity search. This allows AI systems to quickly find relevant vectors based on their similarity to a query vector, even in large-scale datasets with millions or billions of vectors.
Scalability and Performance
Vector databases are built to scale horizontally, meaning they can distribute the workload across multiple nodes in a cluster. This allows them to handle massive amounts of high-dimensional data and support high-throughput, low-latency queries. As the dataset grows, vector databases can seamlessly scale out by adding more nodes to the cluster, ensuring consistent performance and availability.
Flexibility and Extensibility
Vector databases provide a flexible and extensible platform for AI applications. They support a wide range of data types, including text, images, audio, and video, and can easily integrate with popular AI frameworks and libraries, such as TensorFlow, PyTorch, or scikit-learn. Vector databases also offer APIs and SDKs in multiple programming languages, making it easy for developers to build and deploy AI applications on top of them.
Cost-Effectiveness
Using vector databases can be cost-effective for AI applications, especially when compared to traditional databases or custom-built solutions. Vector databases are optimized for storing and searching high-dimensional data, which means they require less storage space and computational resources than other approaches. Additionally, many vector databases are available as open-source software or cloud-based services, which can reduce the upfront costs and maintenance overhead for AI projects.
Semantic Search: Enhancing Information Retrieval with Vector Databases
One of the most promising applications of vector databases in AI is semantic search. Semantic search is a type of information retrieval that focuses on understanding the meaning and context of queries and documents, rather than just matching keywords.
How Semantic Search Works
In traditional keyword-based search, the system looks for exact matches between the query terms and the words in the documents. This approach can be limiting because it doesn’t take into account the semantic relationships between words or the context in which they appear.
Semantic search, on the other hand, uses machine learning techniques to represent queries and documents as high-dimensional vectors, capturing their semantic meaning. By comparing the similarity between these vectors, the system can find documents that are semantically related to the query, even if they don’t contain the exact same keywords.
Here’s a simple example to illustrate the difference between keyword-based search and semantic search:
Let’s say a user searches for “how to make a cake”.
- In keyword-based search, the system would look for documents that contain the words “how”, “to”, “make”, “a”, and “cake”. It might return results like “how to make a cake from scratch” or “easy cake recipes”, but it would miss documents that use different words to describe the same concept, such as “baking a sponge cake” or “cake preparation guide”.
- In semantic search, the system would represent the query and documents as vectors in a high-dimensional space, based on their semantic meaning. It would then find documents that are semantically similar to the query vector, even if they use different words. For example, it might return results like “tips for baking a perfect cake” or “step-by-step cake decorating tutorial”, because they are semantically related to the user’s intent of making a cake.
Benefits of Semantic Search
Semantic search offers several benefits over traditional keyword-based search:
- Improved relevance: By understanding the semantic meaning of queries and documents, semantic search can return more relevant results that better match the user’s intent.
- Increased recall: Semantic search can find relevant documents that use different words or phrases to express the same concept, increasing the recall of the search results.
- Language independence: Semantic search can work across different languages, because it focuses on the meaning of the text rather than the specific words used.
- Personalization: By learning from user interactions and feedback, semantic search can adapt to individual preferences and provide personalized search results.
Implementing Semantic Search with Vector Databases
Vector databases provide an ideal platform for implementing semantic search, because they are designed to store and search high-dimensional vectors efficiently. Here’s a typical workflow for building a semantic search system with a vector database:
- Data preparation: Convert the documents in the corpus into a suitable format for embedding, such as plain text or pre-processed tokens.
- Embedding generation: Use a pre-trained language model, such as BERT or word2vec, to generate vector embeddings for each document in the corpus.
- Vector indexing: Load the document embeddings into a vector database and build an index to enable fast similarity search.
- Query processing: When a user submits a query, convert it into a vector embedding using the same language model as in step 2.
- Similarity search: Use the vector database to find the most similar document embeddings to the query embedding, based on a similarity metric such as cosine similarity or Euclidean distance.
- Result ranking: Rank the search results based on their similarity scores and return them to the user.
By leveraging the power of vector databases and semantic embeddings, AI systems can deliver more accurate and relevant search results, improving the user experience and unlocking new possibilities for information retrieval.
Recommendation Systems: Personalized Suggestions Powered by Vector Databases
Another key application area for vector databases in AI is recommendation systems. Recommendation systems are AI-powered tools that suggest relevant items, such as products, content, or services, to users based on their preferences, behavior, and context.
The Role of Vector Databases in Recommendation Systems
Vector databases play a crucial role in modern recommendation systems by enabling efficient storage and retrieval of high-dimensional user and item vectors. These vectors capture the latent features and relationships between users and items, allowing the recommendation system to find similar users or items and generate personalized suggestions.
Here are some common approaches to building recommendation systems with vector databases:
- Collaborative Filtering: This approach uses the past behavior of users, such as ratings or purchases, to find similar users and recommend items that these similar users have liked. The user-item interactions are represented as sparse vectors, which are then transformed into dense embeddings using techniques like matrix factorization or neural networks. The resulting user and item embeddings are stored in a vector database, enabling fast similarity search to find similar users or items.
- Content-Based Filtering: This approach recommends items to users based on the similarity between the items’ attributes and the user’s preferences. The item attributes, such as text descriptions, images, or metadata, are converted into vector embeddings using techniques like word2vec, CNN, or autoencoders. The user preferences are also represented as vectors, either explicitly provided by the user or inferred from their past interactions. The vector database is used to store and search the item embeddings, finding the most similar items to the user’s preference vector.
- Hybrid Approaches: Hybrid recommendation systems combine collaborative and content-based filtering to overcome the limitations of each approach, such as the cold-start problem for new users or items. Hybrid approaches use vector databases to store and search both user and item embeddings, enabling seamless integration of different data sources and algorithms.
Benefits of Using Vector Databases for Recommendation Systems
Using vector databases for recommendation systems offers several benefits:
- Scalability: Vector databases can handle large-scale datasets with millions of users and items, enabling real-time recommendations for high-traffic applications.
- Flexibility: Vector databases support various data types and algorithms, allowing recommendation systems to leverage diverse sources of information, such as text, images, or user interactions.
- Personalization: By finding similar users or items in the vector space, recommendation systems can generate highly personalized suggestions that adapt to individual preferences and behavior.
- Explainability: Vector embeddings can capture the latent factors that drive user preferences, providing a basis for explaining and interpreting the recommendations.
Real-World Examples of Vector Database-Powered Recommendation Systems
- E-commerce: Online retailers use vector databases to recommend products to users based on their browsing and purchase history, as well as the product attributes and user reviews. For example, Amazon’s item-to-item collaborative filtering algorithm uses a vector database to find similar products and generate personalized recommendations for each user.
- Media Streaming: Streaming services like Netflix, YouTube, and Spotify use vector databases to recommend movies, videos, or songs to users based on their viewing or listening history, as well as the content features and metadata. By representing users and items as vectors, these services can find similar users or items and generate personalized playlists or watch lists.
- Social Media: Social media platforms like Facebook, Twitter, and LinkedIn use vector databases to recommend friends, pages, or content to users based on their social connections, interests, and engagement patterns. By embedding users and content into a shared vector space, these platforms can find similar users or content and generate personalized feeds or notifications.
Computer Vision Applications: Leveraging Vector Databases for Image and Video Search
Computer vision is another field where vector databases are making a significant impact. By representing images and videos as high-dimensional vectors, AI systems can perform efficient similarity search and enable powerful applications like visual search, object recognition, and content-based retrieval.
Image Embeddings and Similarity Search
The key to using vector databases for computer vision is to convert images into vector embeddings that capture their visual features and semantics. This is typically done using deep learning models, such as convolutional neural networks (CNNs), that are trained on large-scale image datasets.
The CNN takes an image as input and passes it through multiple layers of convolution, pooling, and activation functions, extracting hierarchical features at different levels of abstraction. The output of the CNN is a dense vector representation of the image, known as an image embedding.
Image embeddings have several desirable properties for similarity search:
- Invariance: They are invariant to small transformations of the image, such as rotation, scaling, or translation, making them robust to variations in viewpoint or pose.
- Semantic similarity: They capture the semantic content of the image, such that visually similar images have similar embeddings, even if they have different pixel values.
- Compactness: They compress the high-dimensional image data into a compact vector representation, enabling efficient storage and retrieval in vector databases.
Once the image embeddings are generated, they are loaded into a vector database and indexed for fast similarity search. When a user submits a query image, the system computes its embedding using the same CNN model and searches the vector database for the most similar image embeddings, based on a distance metric like Euclidean or cosine distance.
Video Embeddings and Temporal Similarity
Vector databases can also be used for video search and retrieval, by representing videos as sequences of image embeddings over time. Each frame of the video is passed through a CNN to generate an image embedding, and the resulting sequence of embeddings is stored in a vector database.
To search for similar videos, the system computes the similarity between the query video and the database videos using a temporal similarity metric, such as dynamic time warping (DTW) or temporal network embeddings. These metrics align the sequences of embeddings and measure their overall similarity, taking into account the temporal order and duration of the visual content.
Applications of Vector Databases in Computer Vision
Vector databases enable a wide range of applications in computer vision, such as:
- Visual search: Find visually similar images or videos in large-scale collections, based on a query image or video clip.
- Object recognition: Identify objects, people, or scenes in images or videos by comparing their embeddings to a pre-trained database of labeled examples.
- Content-based retrieval: Retrieve images or videos based on their visual content, such as color, texture, or shape, without relying on manual annotations or metadata.
- Duplicate detection: Detect near-duplicate images or videos in large datasets by comparing their embeddings and setting a similarity threshold.
- Anomaly detection: Identify unusual or outlier images or videos by measuring their distance from the normal patterns in the embedding space.
By leveraging the power of vector databases and deep learning, computer vision applications can achieve high accuracy, efficiency, and scalability, opening up new possibilities for visual intelligence and automation.
Natural Language Processing (NLP) and Vector Databases
Natural Language Processing (NLP) is a crucial area of AI that focuses on enabling machines to understand, interpret, and generate human language. Vector databases play a significant role in NLP by providing efficient storage and retrieval of word embeddings, sentence embeddings, and document embeddings.
Word Embeddings and Semantic Similarity
Word embeddings are dense vector representations of words that capture their semantic meaning and relationships. They are typically learned from large text corpora using unsupervised learning algorithms, such as word2vec, GloVe, or FastText.
The key idea behind word embeddings is the distributional hypothesis, which states that words that occur in similar contexts tend to have similar meanings. By training a neural network to predict the context words given a target word, word embedding models learn to map semantically similar words to nearby points in the vector space.
Word embeddings have several useful properties for NLP tasks:
- Semantic similarity: Words with similar meanings have similar vector representations, enabling tasks like synonym detection, word analogy, and semantic search.
- Dimensionality reduction: Word embeddings compress the high-dimensional one-hot encoding of words into a compact vector representation, reducing the sparsity and computational complexity of NLP models.
- Transfer learning: Pre-trained word embeddings can be used as input features for downstream NLP tasks, like sentiment analysis, named entity recognition, or machine translation, improving their performance and generalization.
Vector databases provide an efficient way to store and search word embeddings, enabling fast retrieval of semantically similar words or phrases. This is particularly useful for applications like semantic search, question answering, or text classification, where the system needs to find relevant words or documents based on their semantic similarity to a query.
Sentence and Document Embeddings
In addition to word embeddings, vector databases can also store and search sentence embeddings and document embeddings. These are dense vector representations of entire sentences or documents, capturing their semantic meaning and context.
Sentence embeddings are typically generated by averaging or pooling the word embeddings of the constituent words, or by using more advanced models like Skip-Thought, InferSent, or BERT. Document embeddings can be generated by aggregating the sentence embeddings, or by using models like doc2vec or LDA.
Sentence and document embeddings enable various NLP applications, such as:
- Text similarity: Find similar sentences or documents based on their semantic content, enabling tasks like plagiarism detection, text clustering, or recommendation systems.
- Text classification: Classify sentences or documents into predefined categories, like sentiment, topic, or intent, based on their embedding similarity to labeled examples.
- Text generation: Generate coherent and diverse text by sampling or interpolating in the embedding space, enabling applications like chatbots, language models, or creative writing.
Vector databases provide a scalable and efficient solution for storing and searching sentence and document embeddings, enabling real-time NLP applications that can handle large volumes of text data.
Choosing the Right Vector Database for Your AI Application
When building an AI application that relies on vector embeddings, choosing the right vector database is crucial for achieving high performance, scalability, and ease of use. Here are some key factors to consider when selecting a vector database:
Performance and Scalability
The vector database should be able to handle large-scale datasets with millions or billions of high-dimensional vectors, and provide fast and accurate similarity search results in real-time. Look for databases that use efficient indexing and search algorithms, such as HNSW, IVF, or PQ, and can scale horizontally across multiple nodes or machines.
Data Types and Models
The vector database should support the data types and models used in your AI application, such as text, images, audio, or video. It should also be compatible with popular machine learning frameworks and libraries, such as TensorFlow, PyTorch, or scikit-learn, and provide easy-to-use APIs and integrations.
Ease of Use and Deployment
The vector database should be easy to install, configure, and use, with clear documentation and examples. It should also provide flexible deployment options, such as on-premises, cloud, or hybrid, and support common operating systems and architectures.
Community and Ecosystem
The vector database should have a vibrant and active community of users and developers, who contribute to its development, provide support and feedback, and share best practices and use cases. Look for databases with a strong ecosystem of plugins, extensions, and integrations, as well as regular updates and bug fixes.
Cost and Licensing
The vector database should have a transparent and affordable pricing model, with options for both open-source and commercial licenses. Consider the total cost of ownership, including hardware, software, and maintenance costs, as well as the scalability and performance benefits of each option.
Some popular vector databases that meet these criteria include:
- Faiss: Developed by Facebook AI Research, Faiss is a high-performance vector similarity search library that can handle billion-scale datasets. It provides efficient indexing and search algorithms, such as IVF and PQ, and can be used as a standalone library or integrated with other databases like Redis or PostgreSQL.
- Annoy: Developed by Spotify, Annoy is a lightweight and easy-to-use library for approximate nearest neighbor search. It uses random projection trees to build an index and provides fast and accurate similarity search results, with support for Euclidean and cosine distances.
- ElasticSearch: ElasticSearch is a popular open-source search and analytics engine that provides native support for vector similarity search. It uses the Dense Vector field type to store and index high-dimensional vectors, and provides fast and scalable search results using the
script_scorefunction.
Real-World Use Cases and Success Stories
Vector databases have been successfully applied in various real-world AI applications, across different industries and domains. Here are a few notable use cases and success stories:
- Pinterest – Visual Search and Recommendation: Pinterest, a popular image sharing and social media platform, uses vector databases to power its visual search and recommendation features. By representing images as embeddings and storing them in a vector database, Pinterest can find visually similar images in real-time and provide personalized recommendations to users based on their interests and behavior.
- Spotify – Music Recommendation: Spotify, a leading music streaming service, uses vector databases to generate personalized playlists and song recommendations for its users. By representing songs, artists, and user preferences as embeddings and storing them in a vector database, Spotify can find similar songs and artists and create tailored playlists that match each user’s unique taste.
- Amazon – Product Recommendation: Amazon, the world’s largest e-commerce company, uses vector databases to power its product recommendation engine. By representing products and user behaviors as embeddings and storing them in a vector database, Amazon can find similar products and users and generate personalized recommendations that drive sales and customer satisfaction.
- Google – Semantic Search and Question Answering: Google, the leading search engine and AI company, uses vector databases to enable semantic search and question answering in its products, such as Google Search and Google Assistant. By representing text and images as embeddings and storing them in a vector database, Google can find relevant results and provide accurate answers to users’ queries, even if they use different words or phrases.
- OpenAI – Language Modeling and Text Generation: OpenAI, a leading AI research company, uses vector databases to train and serve its state-of-the-art language models, such as GPT-3. By representing words, sentences, and documents as embeddings and storing them in a vector database, OpenAI can generate coherent and diverse text outputs and enable various applications, such as chatbots, content creation, and language translation.
These are just a few examples of how vector databases are being used in real-world AI applications. As more companies and organizations adopt vector databases and embedding techniques, we can expect to see even more innovative and impactful use cases in the future.
Conclusion
Vector databases are a powerful and promising technology for AI applications that rely on high-dimensional data and similarity search. By representing complex data types, such as text, images, audio, and video, as dense vector embeddings and storing them in specialized databases, AI systems can perform efficient and accurate similarity search and enable various applications, such as semantic search, recommendation systems, and computer vision.
The key benefits of using vector databases in AI include:
- Efficient storage and retrieval of high-dimensional data
- Fast and accurate similarity search results in real-time
- Scalability to handle large-scale datasets and high-throughput workloads
- Flexibility to support various data types, models, and frameworks
- Ease of use and integration with existing AI pipelines and applications
As the field of AI continues to advance and the volume and complexity of data grows, vector databases will become an increasingly essential component of modern AI systems. By leveraging the power of vector databases and embedding techniques, AI practitioners and researchers can unlock new possibilities for intelligent applications and push the boundaries of what is possible with AI.
FAQs
- What are vector databases? Vector databases are specialized databases that are designed to store, index, and search high-dimensional vectors efficiently. They provide fast and scalable similarity search capabilities for applications that deal with large-scale datasets and complex data types, such as text, images, audio, and video.
- What are embeddings? Embeddings are dense vector representations of data that capture the semantic meaning and relationships between different data points. They are typically learned from large datasets using machine learning algorithms, such as neural networks, and can be used to perform various tasks, such as similarity search, classification, and clustering.
- What are the benefits of using vector databases in AI? Vector databases provide several key benefits for AI applications, including efficient storage and retrieval of high-dimensional data, fast and accurate similarity search, scalability to handle large-scale datasets, flexibility to support various data types and models, and ease of use and integration with existing AI pipelines.
- What are some common use cases for vector databases in AI? Vector databases are used in various AI applications, such as semantic search, recommendation systems, computer vision, natural language processing, and anomaly detection. They enable efficient similarity search and retrieval of relevant data points based on their vector embeddings, and can power intelligent features like personalized recommendations, visual search, and question answering.
- What are some popular vector databases used in AI? Some popular vector databases used in AI include Faiss, Annoy, Elasticsearch, and Milvus. These databases provide high-performance similarity search and indexing capabilities for large-scale datasets, and can be used as standalone libraries or integrated with other databases and frameworks.
- How do I choose the right vector database for my AI application? When choosing a vector database for your AI application, consider factors such as performance and scalability, data types and models supported, ease of use and deployment, community and ecosystem support, and cost and licensing. Evaluate different options based on your specific requirements and use case, and test them with realistic datasets and workloads to ensure they meet your needs.
- Can vector databases be used with deep learning models? Yes, vector databases are commonly used with deep learning models, such as convolutional neural networks (CNNs) and transformers, to store and search the vector embeddings generated by these models. Deep learning models can be used to learn high-quality embeddings from raw data, such as images or text, which can then be indexed and searched efficiently using vector databases.
- How do vector databases handle data privacy and security? Vector databases can handle data privacy and security by using techniques such as encryption, access control, and data anonymization. Some vector databases also provide features like secure multi-party computation and federated learning, which allow multiple parties to collaboratively train and use AI models without sharing raw data. It’s important to choose a vector database that meets your specific security and compliance requirements, and to follow best practices for data governance and protection.